



Featuring a 120X boost in capability as opposed to CPUs for AI-powered video as well as a 99% boost in efficiency, this chip is a major game changer for AI applications.
It was in 2012 that a team comprising researchers from Nvidia and Stanford figured out it takes just 12 GPUs to do the job of 2,000 CPUs for AI-related tasks like running LLMs or Deep Learning Algorithms. For more information on that particular story, you might want to read our post on how video games changed the way we process data and paved the way for the biggest AI breakthroughs thus far. Getting back to our story, it was four years later in 2016 that Jensen Huang, CEO of Nvidia built the first AI server, specifically designed for AI-related tasks and built with 8 GPUs, each able to do in 2 hours what a CPU would take 6 days to do. This he hand-delivered to Elon Musk and Sam Altman, the founders of open AI, parent company to the infamous ChatGPT.

L4 on Google Cloud
The rest, of course, is history with Nvidia becoming the brains behind ChatGPT which uses about 10,000 Nvidia GPUs to do what it does, and while these GPUs can still be called graphics cards, they’re built specifically for large-scale AI inference, not video games. Earlier last year, Nvidia released the L4 tensor core GPUs based on the ada lovelace architecture which particularly benefits generative AI models and LLMs like Chat GPT. Boasting twice the performance of the previous T4 tensor core GPUs, the L4s are also cost-effective while consuming significantly less energy. While Google was the first CSP to offer L4 instances in the cloud, there are now several L4 GPU cloud offerings including those from AWS, IBM, and RedHat OpenShift.
Google’s first L4 GPU offerings were on its G2 virtual machines about a year ago when Google announced the Nvidia inference platform was to be integrated with Google Cloud vertex. Featuring a 120X boost in capability as opposed to CPUs for AI-powered video as well as a 99% boost in efficiency, this chip is a major game changer for AI applications. The 200 Tensor cores in the L4 GPUs have been built from the ground up with image generation in mind, making it of particular interest to organizations planning to deploy SDXL (Stable Diffusion XL, aka Generative AI) in production. Last month, Google announced the general availability of the L4 GPU on its Immersive Stream for XR, its service for streaming, rendering, and hosting 3D, as well as Extended Reality (XR) experiences in the cloud.

L4 on IBM Cloud and AWS
Advertising the L4GPUs as having 2.5 times the capability of the previous generation of GPUs for generative AI, IBM has launched its GX3 suite which is available on IBM Cloud Kubernetes Service, as well as RedHat OpenShift. Aimed at developers looking for a 4X boost in graphic performance while generating cinematic quality graphics, IBM also points out that it’s doing its bit to fight climate change since the L4 GPU has a very low carbon footprint. Getting started with your L4 GPUs on IBM Cloud is pretty straightforward and all you need is Kubernetes version 1.28 or later. The drivers are installed automatically and your cluster is provisioned with GX3 worker nodes. It’s pretty much the same for RedHat OpenShift where you install a GPU operator that automates the process for you.

AWS, the cloud leader, has a relationship with Nvidia that goes back about 13 years and has an L4 GPU offering of its own called the EC2 G6 instance. Advertised as an energy-efficient and low-cost solution for Generative AI, this product is aimed at AWS customers looking to run NLPs, create and render in real-time, stream games, or perform real-time language translation.
The key word here is generative, and a good example of Generative AI running on the L4 GPUs in the cloud is Wombo’s Dream app. Dream is a text-to-image AI app that takes a text description of a picture from a user and then uses that description to create stunning AI images. Dream runs on the Nvidia L4 Inference Platform on the Google Cloud.
Personalized AI
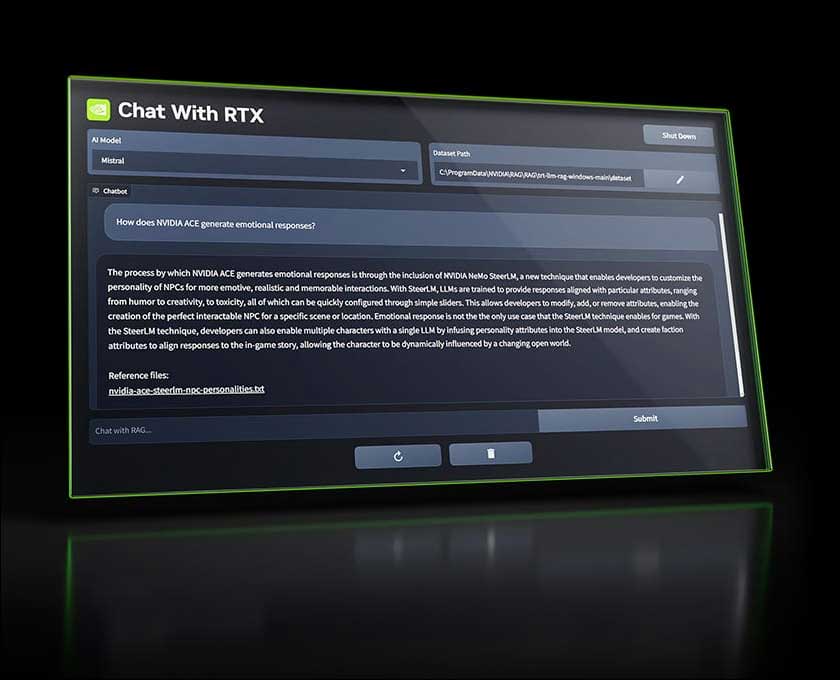
For those who believe in independence from the cloud, and cloud services, Nvidia last month released Chat with RTX, a ChatGPT-style AI assistant that can run locally on a computer with an RTX graphics card. While people who have tried it claim it is still quite rough around the edges, that’s an incredible leap from 10,000 GPUs to a local system with one graphics card. With the stakes higher than ever in the AI world (much of which is thanks to Nvidia), many worry about Nvidia monopolizing the market, much like Microsoft did in the early days of Windows. That being said, however, it wouldn’t be completely wrong to say that none of the breakthroughs with AI would be where they are today without Nvdia or Jenson Huang’s vision for the future.
In case you missed:
- Nvidia Project GROOT for humanoid robots
- What’s Nvidia doing in the restaurant business?
- Could Quantum Gaming Become a Thing?
- TikTok parent company creates KubeAdmiral for Kubernetes
- These AI powered devices add smells to virtual worlds
- Mainstream AI workloads too resource-hungry? Try Hala Point, Intel’s largest Neuromorphic computer
- This Device can Actually Record Your Dreams Like a Movie!
- How AI Is Helping Restore the World’s Coral Reefs
- Meet Einstein Copilot, Salesforce’s new conversational AI
- Could This Tiny Device Really save Us from Our Screens?





